参考文章:
- https://www.pianshen.com/article/15191431794/
- https://blog.csdn.net/qq_40900196/article/details/88998290
BiGRU-Attention 模型
BiGRU-Attention 模型共分为三部分:文本向量化输入层、 隐含层和输出层。其中,隐含层由 BiGRU 层、attention 层和 Dense 层(全连接层)三层构成。BiGRU-Attention 模型结构如图 6 所示。
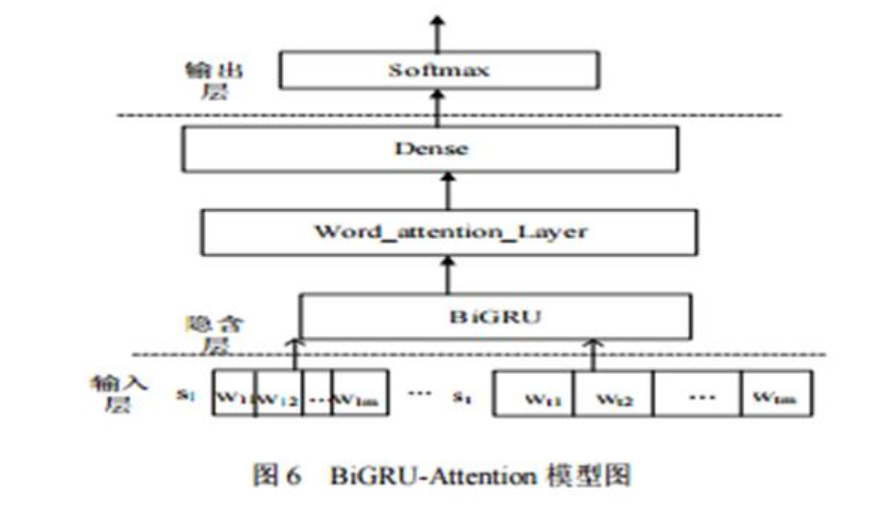
下面对这三层的功能分别进行介绍:
1. 输入层
输入层即文本向量化输入层主要是对IMDB电影评论的25 000条数据的预处理。即把这些评论数据处理成 BiGRU 层能够直接接收并能处理的序列向量形式。m 个单词组成 l 个句子的文本 a 即 a = {$s1, s_2, \cdot\cdot\cdot ,s_l$}, 样本中的第 j 个句子表示为 $s_j $ = { $ w{j1} , w{j2} , \cdot\cdot\cdot , w{jm}$ },进行文本向量操作,使 $ w \in w^a$。文本向量化具体操作步骤如下:
a)读取数据并进行数据清洗;
b)将数据向量化为规定长度 1000 的形式(句子长度小于规定值的,默认自动在后面填充特殊的符号;句子长度大于规定值的,默认保留前 1000 个,多余部分截去。)
c)随机初始化数据,按 8:2 划分训练集和测试集;
d)将数据向量化后,每一条电影评论都变成了统一长度的索引向量,每一个索引对应一个词向量。
经过上面的四步的操作之后,输入的 IMDB 数据就变成根据索引对应词向量的形成词矩阵,即设处理后词向量的统一长度为1000,使用 glove.6B.100d 的 100 维向量的形式,在 glove.6B.100d 中不能查找到的词向量随机初始化。设 $c{ji}$ 为第 j 个句子的第 i 个词向量,则一条长度为 1000 的 IMDB 评论数据可以表示为:
$ c{j1:j1000} = c{j1} \oplus c{j2} \oplus \cdot\cdot\cdot \oplus c_{j1000} $
其中:$c{j1:j1000}$ 表示词向量与词向量的连接操作符,$c{j1:j1000}$ 表示为 $c{j1}, c{j2} \cdot\cdot\cdot c_{j1000} $ 即为第 j 个句子的词向量矩阵。把 IMDB 每一条评论中的每一个词按照索引去对应 glove.6B.100d 中词向量,生成词向量矩阵。
2. 隐含层
隐含层的计算主要分为两个步骤完成:
a) 计算 BiGRU 层输出的词向量。文本词向量为 BiGRU 层的输入向量。BiGRU 层的目的主要是对输入的文本向量进行文本深层次特征的提取。根据 BiGRU 神经网络模型图,可以把 BiGRU 模型看做由向前 GRU 和反向 GRU 两部分组成,在这里简化为式(11)。在第 i 时刻输入的第 j 个句子的第 t 个单词的词向量为 $c{ijt}$ ,通过 BiGRU 层特征提取后,可以更加充分地学习上下文之间的关系,进行语义编码,具体计算公式如式(11)所示。
$h{ijt} = BiGRU(c_{ijt}) , t \in [1,m] \qquad(11)$b)计算每个词向量应分配的概率权重。这个步骤主要是 为不同的词向量分配相应的概率权重,进一步提取文本特征,突出文本的关键信息。在文本中,不同的词对文本情感分类起着不同的作用。地点状语、时间状语对文本情感分类来说,重要程度极小;而具有情感色彩的形容词对文本情感分类却至关重要。 为了突出不同词对整个文本情感分类的重要度, BiGRU-Attention 模型中引入了 attention 机制层。Attention 机制层的输入为上一层中经过 BiGRU 神经网络层处理的输出向量 $h{ijt}$ ,attention 机制层的权重系数具体通过以下几个公式进行计算:
$ u{ijt} = tanh(wwh{ijt} + bw)$
$ \alpha{ijt} = \frac{exp(u{ijt}^Tu_w)}{ \sum_i exp(u{ijt}^Tuw)} \qquad\qquad\qquad (12) $
$ s{ijt} = \sum{i=1}^n \alpha{ijt} h_{ijt} $
其中: $h_{ijt}$ 为上一层 BiGRU 神经网络层的输出向量, $w_w$ 表示权重系数, $b_w$ 表示偏置系数, $u_w$ 表示随机初始化的注意力矩阵。 Attention 机制矩阵由 attention 机制分配的不同概率权重与各个隐层状态的乘积的累加和,使用 softmax 函数做归一化操作得到。
3. 输出层
输出层的输入为上一层 attention 机制层的输出。利用 softmax 函数对输出层的输入进行相应计算的方式从而进行文本分类,具体公式如下:
$yj = softmax(w_1s{ijt} + b_1)$
其中: $w_1$ 表示 attention 机制层到输出层的待训练的权重系数矩阵, $b_1$ 表示待训练相对应的偏置, $y_j$ 为输出的预测标签。